Identity Chaining: The Best Security Control You Can’t Buy
A runtime, post-access view of identity → action → data touched across services, tools, and agents.

Security teams learned to love identity. If you can tie actions to a user or service principal, you can reason about least privilege, investigate incidents, and enforce policy.
Then agents arrived, and changed the bar.
“Who had access” is no longer the hard question. The hard question is: what actually happened after access was granted, across a chain of services and tools that does not reliably preserve identity context.
That gap has a name: identity chaining.
Identity chaining is the ability to reliably answer, for any sensitive action:
Who initiated this chain?
Which services and tools executed it?
Which identities were used along the way (human, service account, workload identity, agent identity)?
What data was accessed, transformed, and sent out?
It is one of the most important controls you can have in modern systems, and also the one you usually cannot buy off the shelf.
Because identity chaining is not a feature. It is a contract.
The quiet assumption behind most security tooling
A lot of enterprise security tooling implicitly assumes identity flows cleanly through your stack:
The user authenticates.
The service authorizes.
Logs show the actor.
Downstream systems record who did what.
In simple systems, that is mostly true.
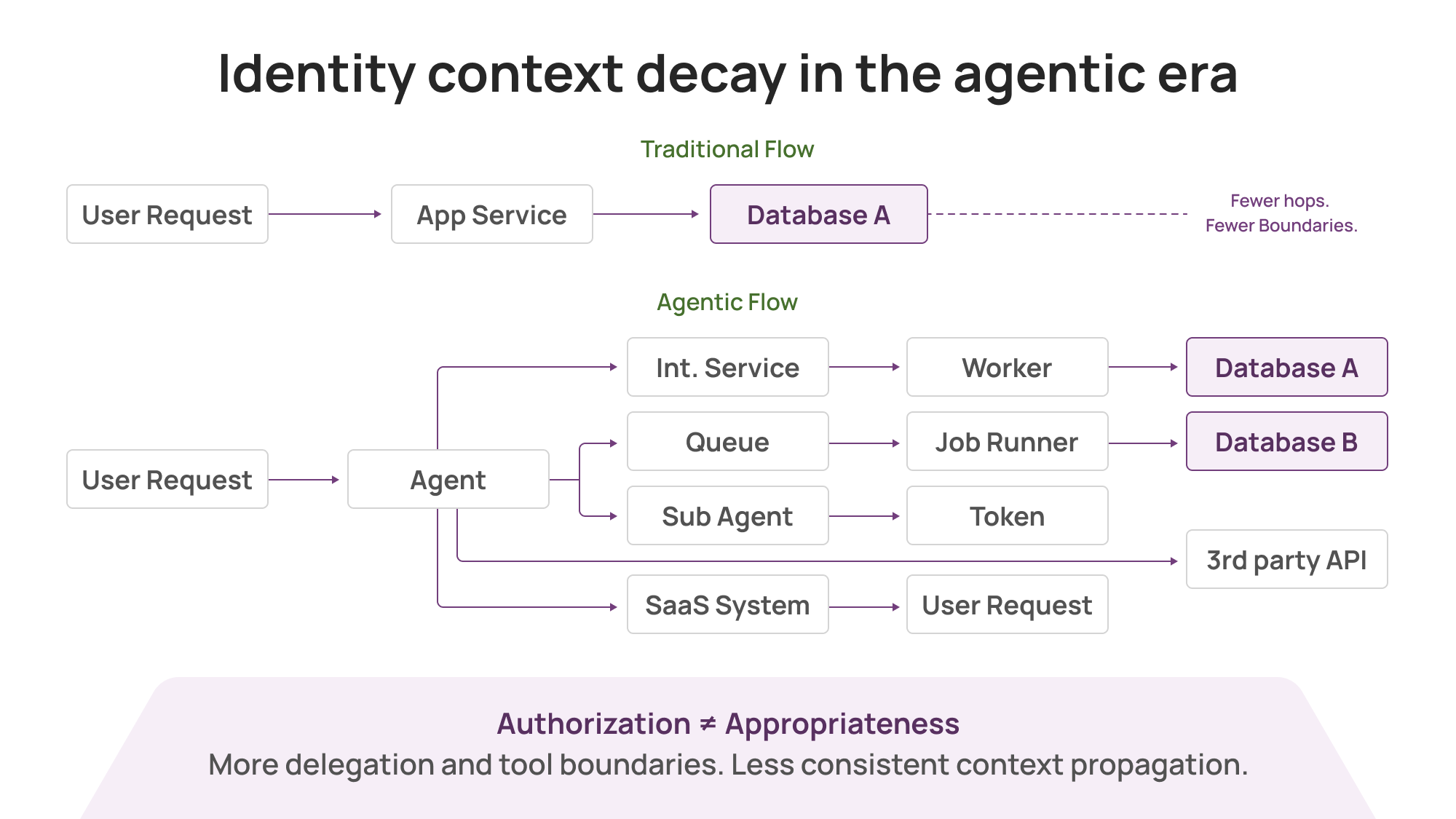
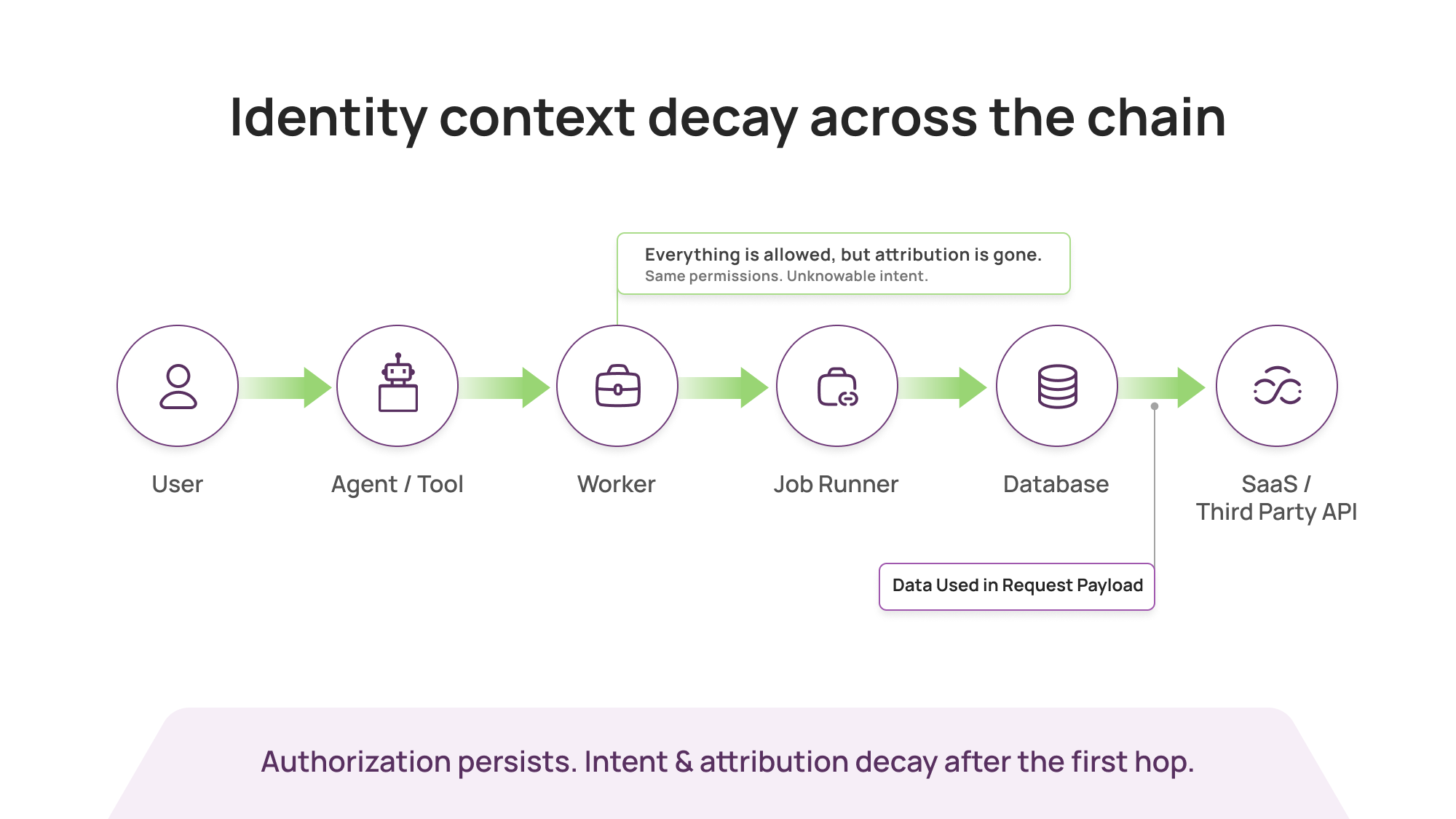
In real systems, identity context decays after the first hop.
A user action triggers a web service. That service calls a worker. The worker calls a job runner. The job runner queries a database and hits a third-party API. Somewhere along the way, the original “who” gets replaced by a “what”: a token, a role session, a workload identity, an access key, a service account.
Everything is technically legitimate. And yet the most important detail is missing.
You cannot reliably tell whether that database query was:
a customer support workflow,
a background job,
a misconfigured service,
a compromised internal tool,
or an agent doing something that is technically allowed, but clearly wrong.
This is why investigations drag. This is why blast radius is hard to assess. Agents amplify the problem by making chains longer, faster, and less predictable.
Why identity chaining matters more in an agentic world
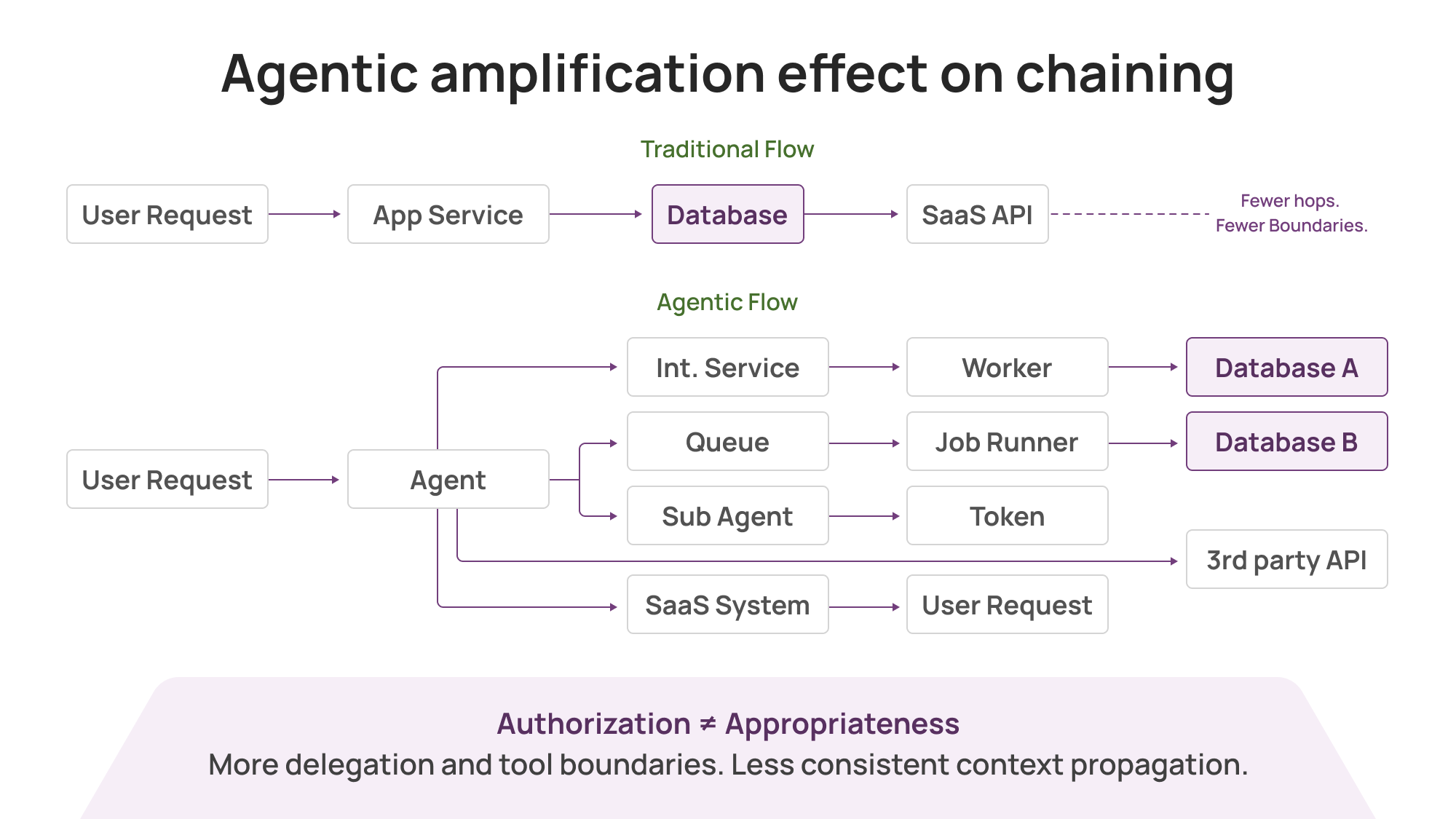
Agentic systems chain tools by design. A single user request can fan out into:
multiple internal services
multiple databases
multiple SaaS systems
multiple third parties
multiple delegated tokens and sub-agents
Even when you do the “right” things (scoped tokens, JIT, least privilege, tool gating), one reality remains: Authorization ≠ Appropriateness. Authorization is a permissions check; appropriateness depends on intent and context.
Agents often need broad permissions to be useful. Their actions are not fully predictable. The security requirement shifts from “was this allowed?” to “what did the chain do, who initiated it, and how quickly can we contain outcomes?”
That is identity chaining.
How Facebook solved identity chaining (and why it does not port easily)
I’ve seen identity chaining done well at Facebook.
It did not come from buying a product. It came from enforcing a standard: every service call was expected to carry viewer context, a structured identity context that captured the originating user, the calling service, the session, and often the reason for access.
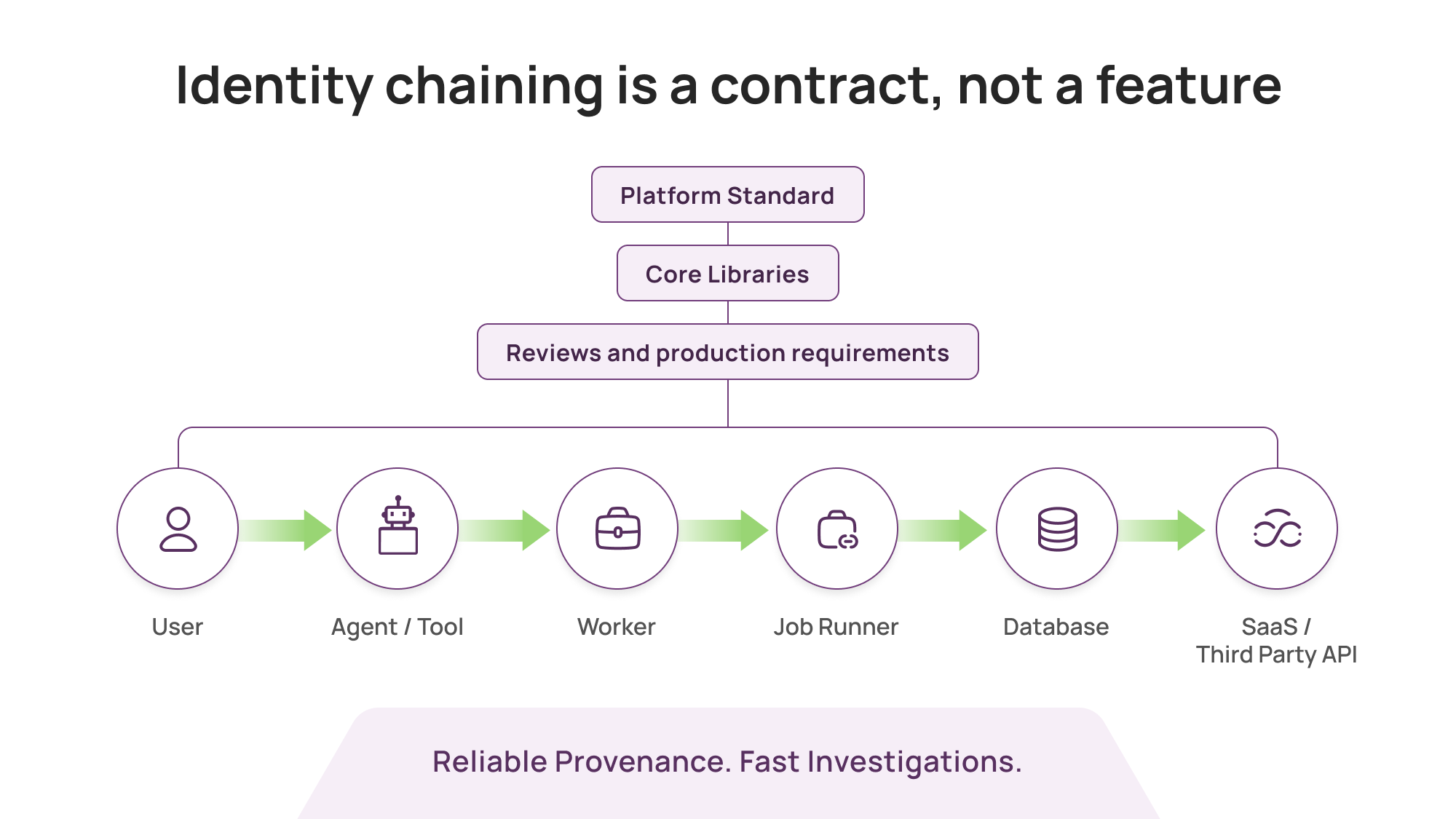
The key was enforcement:
platform teams defined the standard
core libraries made it easy to comply
reviews and production requirements made it mandatory
teams that ignored it paid an operational cost
That is what it takes for identity chaining to be reliable.
Most enterprises cannot replicate this quickly because:
they do not run one platform stack
they do not have one service framework
they do not own every service end to end
they cannot force every team to propagate identity context consistently
they cannot refactor a large legacy estate to pass context cleanly
Many vendors say they support identity chaining. In practice, most can only display identity where it already exists.
Reliable chaining requires identity context to exist everywhere it needs to exist, consistently.
That is why it is so hard to buy.
Why app-layer propagation rarely happens
App-level identity propagation is the cleanest solution. It is also the hardest organizational change to execute.
Doing it properly requires standardizing:
context propagation across HTTP, gRPC, and async queues
structured identity formats and delegation rules
consistent attribution in downstream systems
protection against spoofed or forged context
This is not an installation step. It is a multi-quarter platform program, and it competes with feature delivery. Many organizations only prioritize it after a major incident.
So the practical question becomes: what can you do without changing every app?
The pragmatic path: runtime stitching without app changes
If you cannot enforce identity chaining as a contract, you can infer it from what you can observe.
This is where runtime comes in.
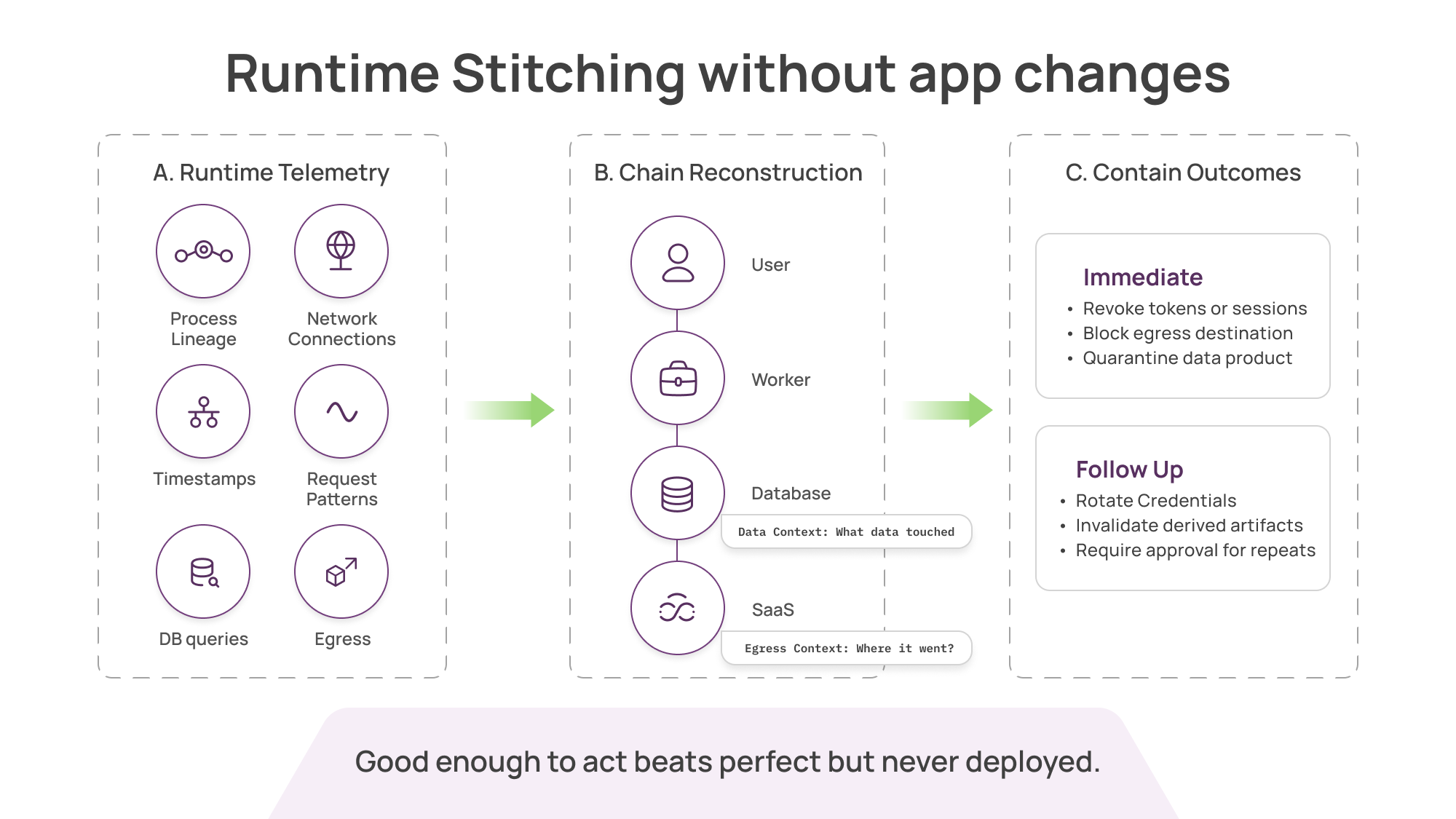
At Aurva, the approach we’ve taken is:
Capture runtime telemetry across the environment without requiring app changes
Reconstruct flows between processes, services, databases, and third parties
Stitch chains using correlation signals such as timestamps, process lineage, connection metadata, and request patterns
Attach data context (what data was touched) and egress context (where it went)
Assign confidence, and improve chaining accuracy over time
This is not as clean as native viewer context propagation. But it has clear advantages:
it works in heterogeneous environments
it covers legacy services
it does not require every app team to comply
it produces real-time, end-to-end evidence that security teams can use immediately
For most security teams, “good enough to act” is better than “perfect but never deployed.”
What is solved today, and what is still hard
Identity chaining has layers.
Some layers are tractable today:
mapping process-to-process and service-to-service flows
identifying access to databases and sensitive stores
detecting unusual access patterns and risky third-party destinations
building investigation timelines quickly
Other layers remain hard:
tying every downstream action back to the originating user when identity was never propagated
disambiguating high-throughput systems where many requests look similar
reconstructing causality across complex async workflows
standardizing agent identity handoff across frameworks and toolchains
We have solved the telemetry and flow visibility problem. Exact chaining is still an evolving frontier. The right strategy is incremental accuracy with immediate operational value.
What security teams should do now
If you are deploying AI and agentic systems, treat identity chaining as a first-class requirement.
Three practical steps:
Stop treating logs as the source of truth
Logs help, but they were not built to reconstruct chains across heterogeneous systems.
Instrument for chain-of-custody, even if it starts probabilistically
You need to answer “what happened” quickly, with evidence.
Design for post-facto containment
For agentic systems, scalable control often looks like: detect quickly, then contain outcomes (revoke tokens, quarantine data products, block egress, rotate credentials, invalidate derived artifacts, require approvals).
If you can do app-level identity propagation, do it. It is still the gold standard.
But do not wait for perfect propagation before you start protecting data. Most breaches happen in the gaps between “we assume identity follows the request” and “we can prove it did.”
Identity chaining is the control that makes investigations and containment possible in modern stacks.
In the agentic era, the bar is simple: can you prove what the chain did with access, and can you contain outcomes fast?
Disclaimer: I’m CEO of Aurva, an AI security company focused on runtime visibility for agentic systems. These views are based on my experience building AI systems at Meta and working with security teams deploying agents in production.