From Discovery to Drift: Securing AI Agents in Production
Identity governance sets intent, and runtime proof is what makes it enforceable

Every agent you deploy into production is a live security question with three parts: can you find it, can you govern it, can you catch the drift.
Right now, most teams can confidently answer maybe one of these. Discovery is catching up, but agents do not all show up the same way. Governance is maturing, but permissions do not predict behavior. And runtime proof is still missing in many stacks, which means agents you already approved are making decisions no one is verifying.
These are not stages. They are three things that need to be true simultaneously.
An agent you cannot find is a shadow risk. An agent you found but cannot govern is an ownership gap. An agent you govern but cannot verify is a trust assumption waiting to break.
This piece is about the lifecycle that makes all three true at once.
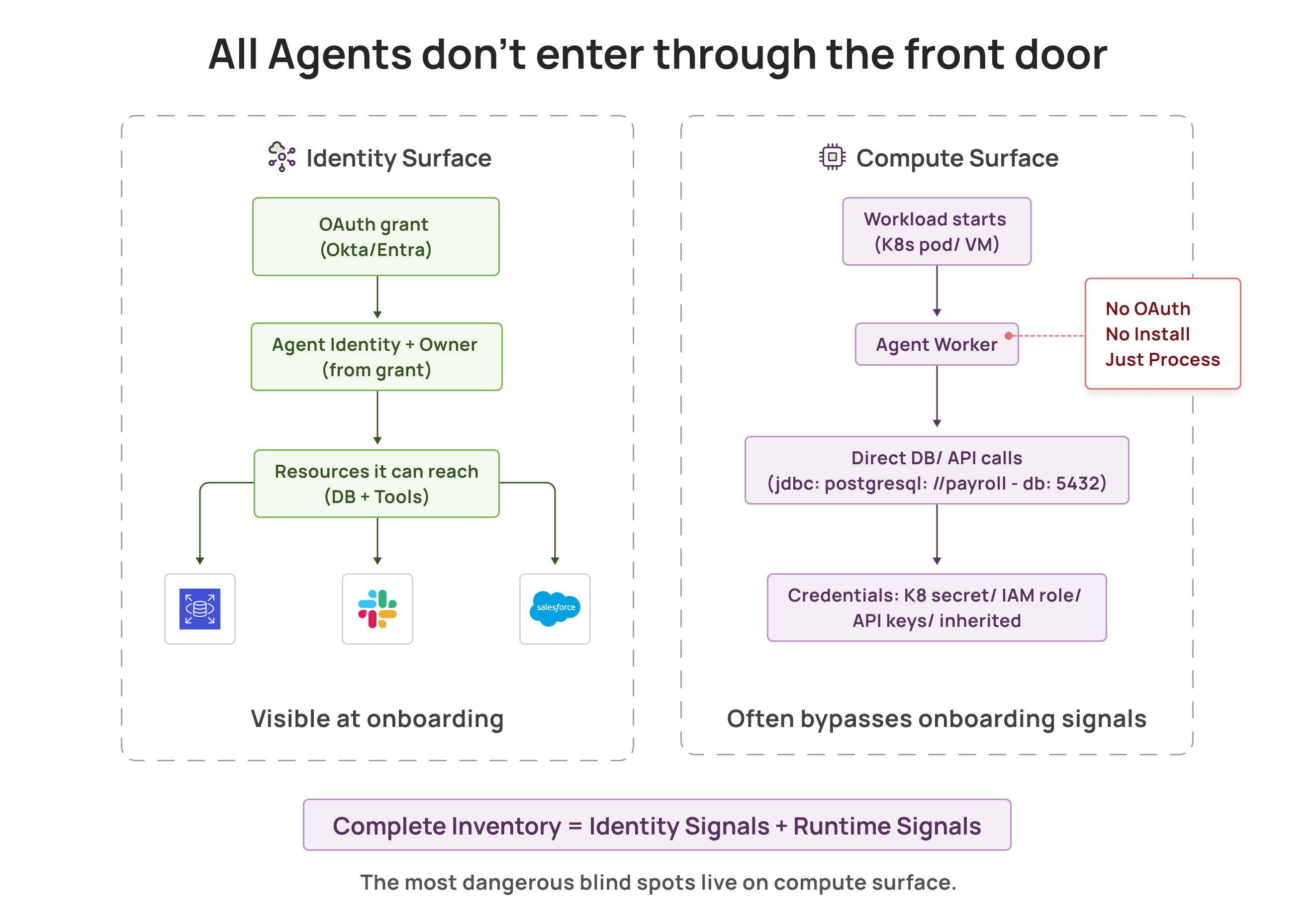
The front door is getting instrumented, but agents do not always use the front door
Agent discovery is finally catching up to shadow AI on the integration surface. Teams can now spot new agentic tools at the moment they are granted access to enterprise apps, map which resources they can reach, and turn discoveries into governed assets with owners and baseline policies.
That is a meaningful shift. It gives visibility before an integration quietly evolves into deeper backend connections and app to app paths.
But there is an entire class of shadow AI this approach often will not see: untracked agent workloads deployed directly onto compute. Kubernetes pods, VMs, dev machines. Agents connecting to databases, internal services, and APIs using connection strings, API keys, or inherited credentials. No consent event. No browser signal. No obvious front door moment.
In many engineering heavy organizations, this is where the harder shadow AI lives, closer to production data and further from any governance process. Unsanctioned agents do not always arrive through integrations. Sometimes they are just processes that show up on your infrastructure and start touching sensitive systems.
So even at onboarding time, there are two discovery surfaces:
Integration surface: agents that show up as access grants and authorized connections to enterprise systems through OAuth flows, SaaS integrations, and related access signals.
Compute surface: agents that show up as workloads running on machines and clusters, including untracked agent workloads that never generated an integration signal.
A complete inventory requires both. And in many organizations, the compute surface is where the more dangerous blind spots hide.
The lifecycle that actually works: discover, govern, contract, monitor, enforce, learn
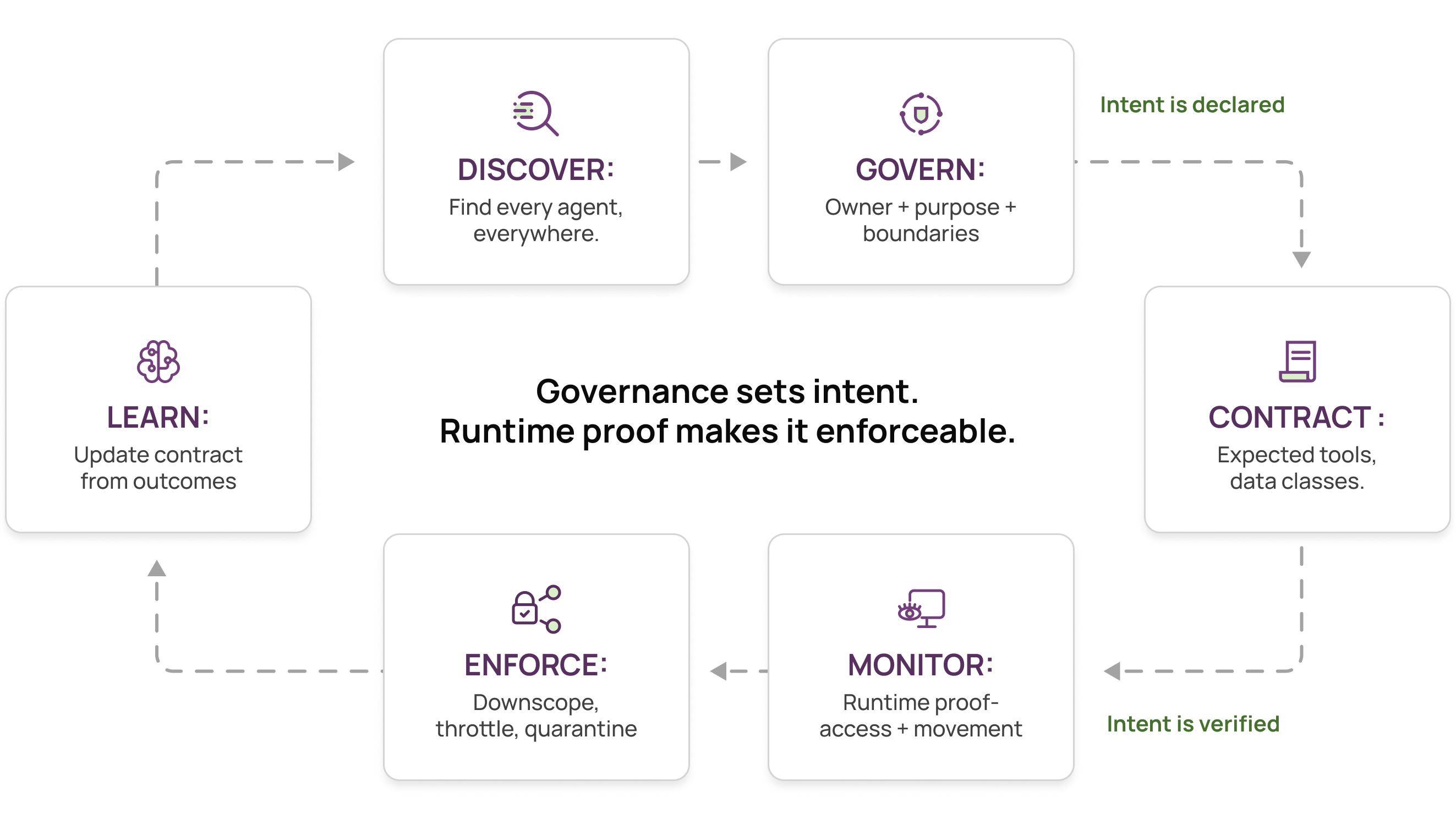
This is not use two tools. It is a lifecycle where each layer does what it is structurally best at, in sequence.
1) Discover everywhere
Discover agents on the integration surface and the compute surface. Together, you get coverage. Separately, you get blind spots.
2) Govern
Put agents under governance with an accountable owner, a declared purpose, and explicit access boundaries. The goal is simple: every agent is accountable, and its intended use is written down.
3) Contract
Define intended behavior. Not just broad permissions, but what on purpose looks like for this agent: sanctioned tools, expected data classes, and approved destinations. This is the behavioral contract. It is not a static ACL. It is a description of intent that can be verified.
4) Monitor
Collect runtime proof of what agents actually do: what they access, at what breadth and volume, which tools they invoke, and where data moves next. This evidence exists whether or not anything anomalous is happening. It is the flight data recorder for your agent fleet.
In practice, teams collect runtime evidence from the workload itself using runtime instrumentation and kernel level telemetry such as eBPF to observe access patterns and data movement independent of how the agent authenticated.
5) Enforce fast
When proof diverges from contract, unusual breadth or volume, a new destination, a tool outside the registry, you trigger enforcement. Downscope access. Throttle. Quarantine. Escalate to a human. The response should happen quickly, not after a morning of log archaeology.
6) Learn
Feed outcomes back into governance. Legitimate behavioral changes update the contract. Risky patterns tighten boundaries. Over time, the system gets less noisy and more decisive.
This is the loop: Runtime proof makes governance real, and Governance context makes runtime evidence actionable.
Most incidents will not start as an unknown agent
The agent incident you will actually get in production often looks like this:
The agent was known.
The permissions were reviewed.
The owner existed.
The data source was allowed.
And the outcome was still bad.
Not because the agent broke out of permissions, but because agents are non deterministic. They choose their next step based on context. The same request can lead to different tool calls, different query shapes, different data breadth, and different destinations each time. Because the policy is static, but the agent’s plan is dynamic.
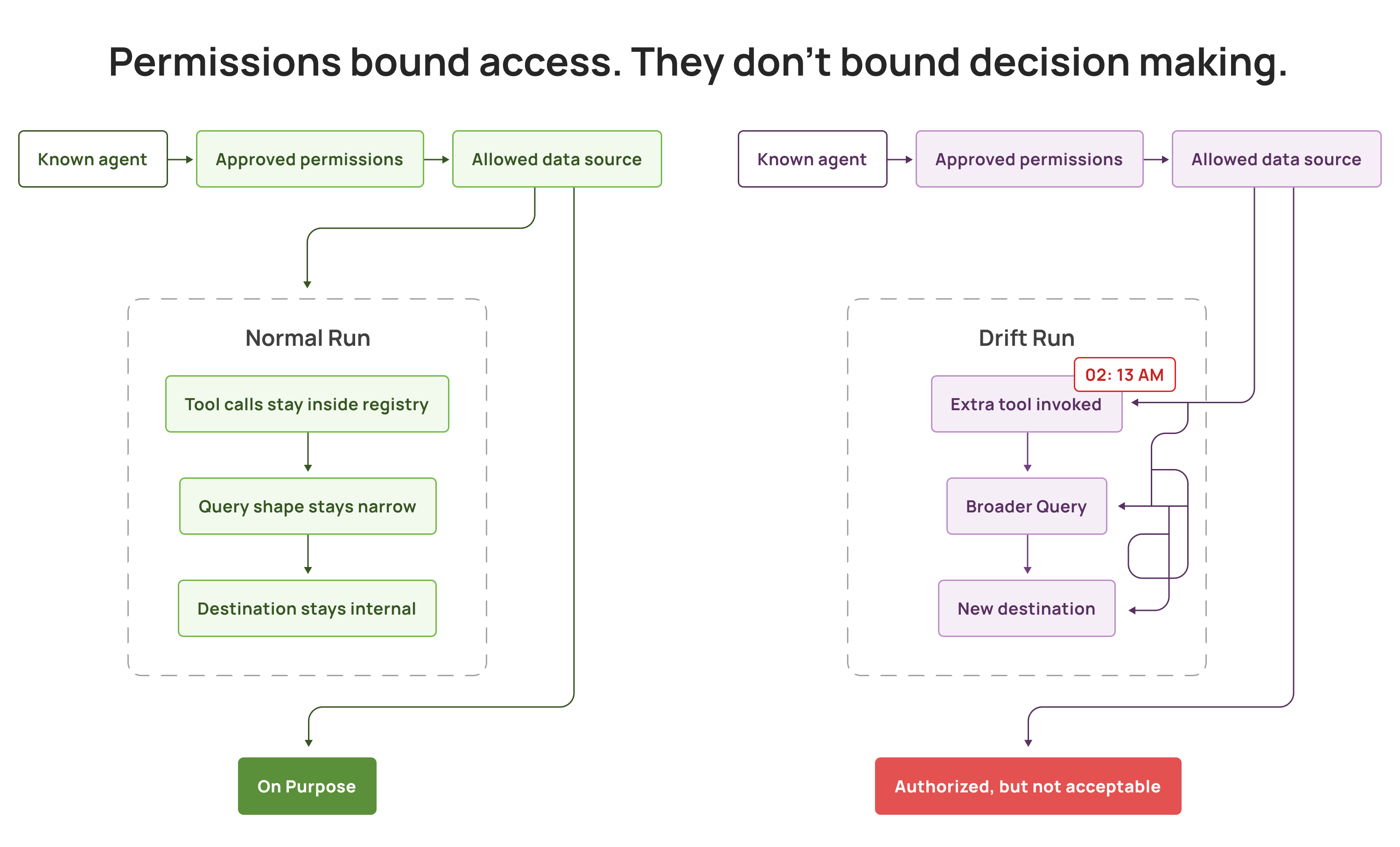
Permissions bound access. They do not bound decision making.
Approved agents can stay inside granted scopes and still:
Pull far more data than expected because the agent decided more context will help.
Chain through tools so effective privilege becomes the union of multiple identities.
Route output to a destination nobody modeled.
Drift over time as prompts, models, tools, retrieval, and workflows evolve.
That is the mismatch at the core: identity and entitlements approve access, but they cannot, by themselves, tell whether the behavior stayed on purpose.
So the real production question becomes:
How do you detect and contain behavioral drift fast enough that authorized does not become acceptable?
Six primitives that make drift measurable
For the loop to work, governance and runtime evidence need a shared vocabulary. These six primitives cover almost every agent incident worth caring about:
Actor: the full attribution chain, triggering user or workflow, orchestrator, delegated identity, credential used.
Tool: SaaS integration, connector, MCP server, internal service, database client.
Action: query, export, write, share, upload, send, grant.
Data: class plus volume and breadth.
Destination: where data moved next, internal system, bucket, external endpoint, another agent.
Purpose: why the agent took the action. Same query, same scope, entirely different risk depending on intent. Purpose is inferred partly from governance context, what the agent is designed to do, and partly from runtime context, whether this sequence matches the agent’s established pattern. When purpose cannot be inferred with confidence, that itself is a signal worth escalating.
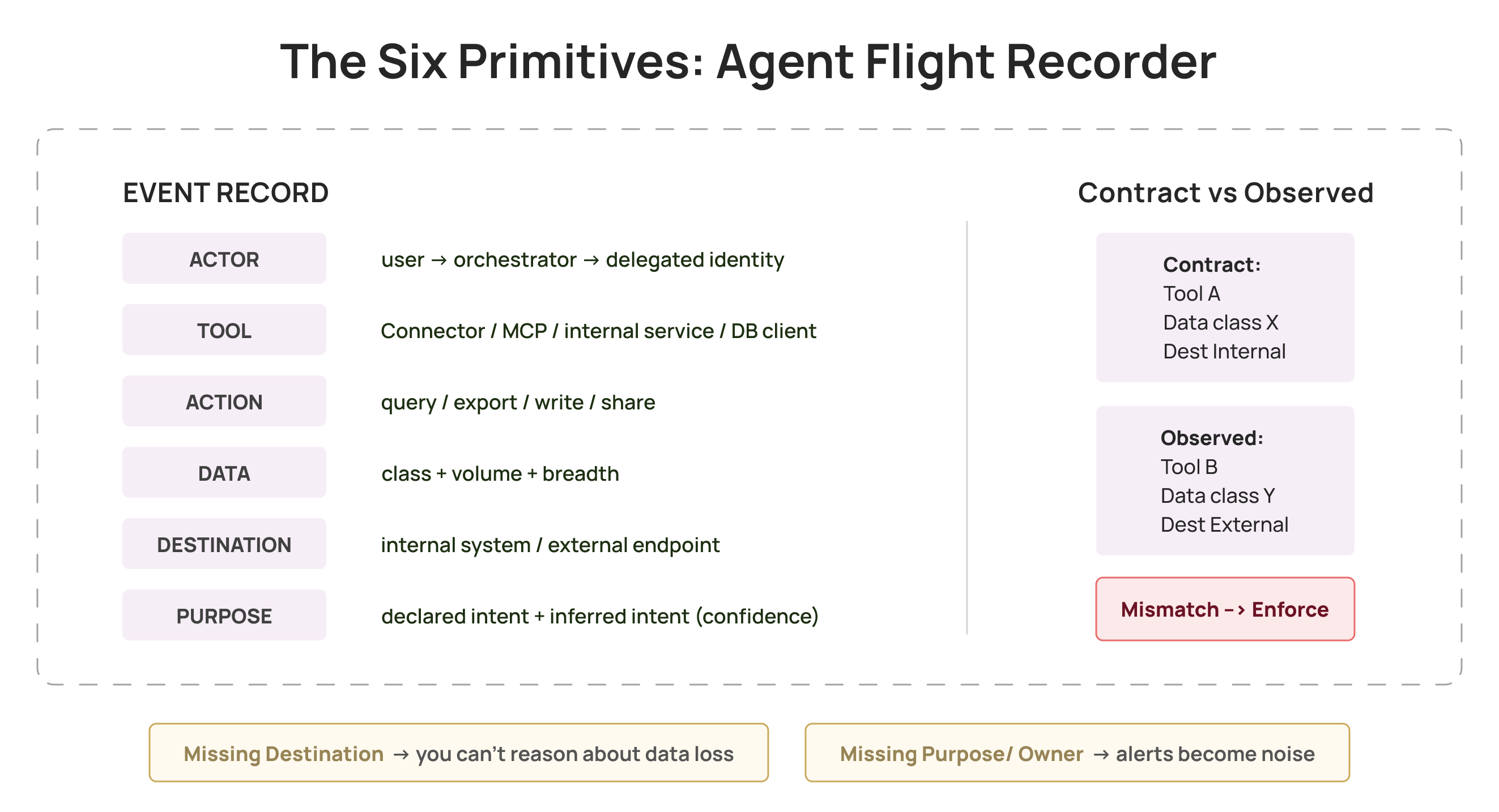
Two quick tests:
If you cannot populate destination, you will struggle to reason about data loss.
If you cannot populate owner and purpose, your alerts will be noisy and hard to act on.
Controls that survive non determinism
Rigid allow or deny rules either break workflows or get bypassed. The controls that work in practice allow flexibility but cap blast radius.
Data budgets
Define how much per session, per task, per day. Budgets do not require predicting behavior. They require metering it.
Destination constraints for sensitive classes
Most incidents become incidents at the destination. If sensitive data can only flow to approved destinations, you reduce worst case outcomes even when behavior is unexpected.
Step up on high risk transitions
Add adaptive friction at the moments drift begins: first time sensitive access, sudden jumps in volume, first time external destination, first time tool invocation.
Novelty as a first class signal
New dataset, new tool, new destination, new time window. Treat novelty as review worthy by default, not logged for later.
A rollout that does not turn into a six month program
If you try to secure all agents, you will stall. A more reliable path:
Start with agents touching sensitive systems.
Deploy runtime observation early to discover what is actually running, including untracked agent workloads that never showed up in governance. You also need enough behavioral data to baseline normal before writing meaningful policies.
Get ownership and purpose right, then define contracts for the highest risk agents first.
Enforce one or two controls that cap worst case outcomes. Data budgets and destination constraints are usually the least controversial.
Keep novelty and drift policies in review mode until tuned.
The goal is not perfect modeling. The goal is fast containment of drift.
A quick sanity check
If an agent goes weird at 2:13am tonight:
How quickly can you answer what did it touch, and where did it send it?
Can you explain who owns it and what it was supposed to do?
Can your system respond fast, without log archaeology?
If those answers are fuzzy, you do not have an agent security system yet. You have partial visibility.
Discovery gets you inventory. Governance sets intent. Runtime evidence contains drift. The teams that do this well close the loop: define the contract, collect proof, contain drift, and learn fast.
And here is the part most teams miss:
Identity without runtime proof is governance theater.
Runtime proof without governance context is noise.
Disclaimer: I’m CEO of Aurva, an AI security company focused on runtime visibility for agentic systems. These views are based on my experience building AI systems at Meta and working with security teams deploying agents in production.